Internet Censorship in Dubai and the UAE
The internet is censored in the UAE. Not really bad like in China – it’s rather used to restrict access to “immoral content”. Because you know, the internet is full of porn and Danish people making fun of The Prophet. – Also, downloading Skype is forbidden (but using it is not).
I have investigated the censorship mechanism of one of the two big providers and will describe the techniques in use and how to effectively circumvent the block.
How it works
If you navigate to a “forbidden page” in the UAE, you’ll be presented with a screen warning you that it is illegal under the Internet Access Management Regulatory Policy to view that page.

This is actually implemented in a pretty rudimentary, yet effective
way (if you have no clue how TCP/IP works). If a request to a
forbidden resource is made, the connection is immediately shut down by
the proxy. In the shutdown packet, an <iframe> code is placed that
displays the image:
<iframe src="http://94.201.7.202:8080/webadmin/deny/index.php?dpid=20&
dpruleid=7&cat=105&ttl=0&groupname=Du_Public_IP_Address&policyname=default&
username=94.XX.0.0&userip=94.XX.XX.XX&connectionip=1.0.0.127&
nsphostname=YYYYYYYYYY.du.ae&protocol=nsef&dplanguage=-&url=http%3a%2f%2f
pastehtml%2ecom%2fview%2fc336prjrl%2ertxt"
width="100%" height="100%" frameborder=0></iframe>
Capturing the TCP packets while making a forbidden request – in this case: a
list of banned URLs in the UAE, which itself is banned – reveals one crucial
thing: The GET request actually reaches the web server, but before the answer
arrives, the proxy has already sent the Reset-Connection-Packets. (Naturally,
that is much faster, because it is physically closer.)
Because the client thinks the connection is closed, it will itself send out Reset-Packets to the Webserver in reply to its packets containing the reply (“the webpage”). This actually shuts down the connection in both directions. All of this happens on the TCP level, thus by “client” I mean the operating system. The client application just opens a TCP socket and sees it closed via the result code coming from the OS.
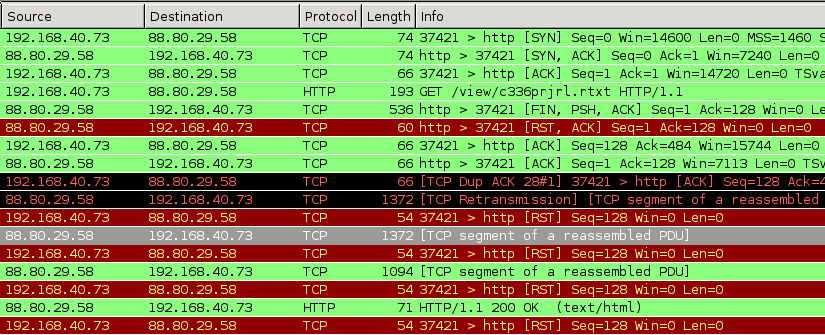
You can see the initial reset-packets from the proxy as entries 5 und 6 in the list; the later RST packets originate from my computer because the TCP stack considers the connection closed.
How to circumvent it
First, we need to find out at which point our HTTP connection is being hijacked. To do this, we search for the characteristic TCP packet with the FIN, PSH, ACK bits set, while making a request that is blocked. The output will be something like:
$ sudo tcpdump -v "tcp[13] = 0x019"
18:38:35.368715 IP (tos 0x0, ttl 57, ... proto TCP (6), length 522)
host-88-80-29-58.cust.prq.se.http > 192.168.40.73.37630: Flags [FP.], ...
We are only interested in the TTL of the FIN-PSH-ACK packets: By substracting this from the default TTL of 64 (which the provider seems to be using), we get the number of hops the host is away. Looking at a traceroute we see that obviously, the host that is 64 - 57 = 7 hops away is located at the local ISP. (Never mind the un-routable 10.* appearing in the traceroute. Seeing this was the initial reason for me to think these guys are not too proficient in network technology, no offense.)
$ mtr --report --report-wide --report-cycles=1 pastehtml.com
HOST: mjanja Loss% Snt Last Avg Best Wrst StDev
1.|-- 192.168.40.1 0.0% 1 2.9 2.9 2.9 2.9 0.0
2.|-- 94.XX.XX.XX 0.0% 1 2.9 2.9 2.9 2.9 0.0
3.|-- 10.XXX.0.XX 0.0% 1 2.9 2.9 2.9 2.9 0.0
4.|-- 10.XXX.0.XX 0.0% 1 2.9 2.9 2.9 2.9 0.0
5.|-- 10.100.35.78 0.0% 1 6.8 6.8 6.8 6.8 0.0
6.|-- 94.201.0.2 0.0% 1 7.7 7.7 7.7 7.7 0.0
7.|-- 94.201.0.25 0.0% 1 8.4 8.4 8.4 8.4 0.0
8.|-- 195.229.27.85 0.0% 1 11.1 11.1 11.1 11.1 0.0
9.|-- csk012.emirates.net.ae 0.0% 1 27.3 27.3 27.3 27.3 0.0
10.|-- 195.229.3.215 0.0% 1 146.6 146.6 146.6 146.6 0.0
11.|-- decix-ge-2-7.i2b.se 0.0% 1 156.2 156.2 156.2 156.2 0.0
12.|-- sth-cty1-crdn-1-po1.i2b.se 0.0% 1 164.7 164.7 164.7 164.7 0.0
13.|-- 178.16.212.57 0.0% 1 151.6 151.6 151.6 151.6 0.0
14.|-- cust-prq-nt.i2b.se 0.0% 1 157.5 157.5 157.5 157.5 0.0
15.|-- tunnel3.prq.se 0.0% 1 161.5 161.5 161.5 161.5 0.0
16.|-- host-88-80-29-58.cust.prq.se 0.0% 1 192.5 192.5 192.5 192.5 0.0
We now know that with a very high probability, all “connection termination” attempts from this close to us – relative to a TTL of 64, which is set by the sender – are the censorship proxy doing its work. So we simply ignore all packets with the RST or FIN flag set that come from port 80 too close to us:
for mask in FIN,PSH,ACK RST,ACK; do
sudo iptables -I INPUT -p tcp --sport 80 \
-m tcp --tcp-flags $mask $mask \
-m ttl --ttl-gt 55 -m ttl --ttl-lt 64 \
-j DROP;
done
NB: This checks for the TTL greater than, so we have to check for greater 56 and substract one to be one the safe side. You can also leave out the TTL part, but then “regular” TCP terminations remain unseen by the OS, which many programs will find weird (and sometimes data comes with a package that closes the connection, and this data would be lost).
That’s it. Since the first reply packet from the server is
dropped, or rather replaced with the packet containing the <iframe>
code, we rely on TCP retransmission, and sure enough, some 0.21 seconds
later the same TCP packet is retransmitted, this time not harmed in
any way:
![]()
The OS re-orders the packets and is able to assemble the TCP stream. Thus, by simply ignoring two packets the provider sends to us, we have an (almost perfectly) working TCP connection to where-ever we want.
Why like this?
I suppose the provider is using relatively old Cisco equipment. For example, some of their documentation hints at how the filtering is implemented. See this PDF, p. 39-5:
When filtering is enabled and a request for content is directed through the security appliance, the request is sent to the content server and to the filtering server at the same time. If the filtering server allows the connection, the security appliance forwards the response from the content server to the originating client. If the filtering server denies the connection, the security appliance drops the response and sends a message or return code indicating that the connection was not successful.
The other big provider in the UAE uses a different filtering technique, which does not rely on TCP hacks but employs a real HTTP proxy. (I heard someone mention “Bluecoat” but have no data to back it up.)
IPv6 ... here I come
Sooo... I'm finally part of the IPv6 world now, and so is this blog. I've been meaning to do this for a long time now, but ... you know. – I ran into some traps – partly my own fault – so I might just share it for others, too.
First of all, and this got me several times, when testing loosen up
your iptables settings. That especially means setting the right
policies in ip6tables: ip6tables -P INPUT ACCEPT. (I had set the
default policy to DROP before automatically at interface-up time.
It's better safe than sorry. Do you know what services listen on ::
by default?)
I started out using a simple
Teredo tunnel, which
worked well enough. See Bart's article
ipv6 on your desktop in 2
steps. The default
gai.conf, used by the glibc to resolve hosts, will still prefer IPv4
addresses over IPv6 if your only access is a Teredo tunnel. You can
change this by commenting out the default label policies in
/etc/gai.conf, except for the #label 2001:0::/32 7 line. (See
here
for example. The blog post advises to reboot or wait 15 minutes, but
for me it was enough to re-start my browser / newsreader / ...)
So I set up IPv6 on my server. This was rather easy because Hetzner provides native v6. The real work is just re-creating the iptables rules, adding new AAAA records for DNS. Strike that: The real work is teaching all your small tools to accept IPv6-formatted addresses. (Great efforts are underway to modernize many programs. But especially your odd Perl script will simply choke on the new log files. :-P)
I am still not sure how I should use all these addresses. For now I
enabled one "main" IP for the server, 2a01:4f8:150:4022::2. Then I
have one for plenz.com and one for the blog,
ending in leet-speak "blog": 2a01:4f8:150:4022::b109 – Is it
useful to enable one ip for every subdomain and service? It sure seems
nice, but also a big administrative burden...
Living with the Teredo tunnel for some hours, I wanted to do it "the right way", i.e. enabling IPv6 tunneling on my router. Over at HE's Tunnelbroker you'll get your free tunnel, suitable for connecting your home network.
I'm still using an old OpenWRT WhiteRussian setup with 2.4 kernel, but everything works surprisingly well, once I figured out how to do it properly. HE conveniently provides commands to set up the tunnel; however, setting up the tunnel creates a default route that routes packets destined to your prefix across the tunnel. (I don't know why this is the case.) Thus, after establishing the tunnel, I'm doing:
# send traffic destined to my prefix via the LAN bridge br0
ip route del <prefix>::/64 dev he-ipv6
ip route add <prefix>::/64 dev br0
Second, I want to automatically update my IPv6 tunnel endpoint
address. HE conveniently provides and IPv4 interface for that. Simply
md5-hash your password via echo -n PASS | md5sum, find out your user
name hash from the login start page (apparently not the md5 hash of
your username :-P) and your tunnel ID. My script looks like this:
root@ndogo:~# cat /etc/ppp/ip-up.d/he-tunnel
#!/bin/sh
set -x
my_ip="$(ip addr show dev ppp0 | grep ' inet ' | awk '{print $2}')"
wget -O /dev/null "http://ipv4.tunnelbroker.net/ipv4_end.php?ipv4b=$my_ip&pass=PWHASH&user_id=UHASH&tunnel_id=TID"
ip tunnel del he-ipv6
ip tunnel add he-ipv6 mode sit remote 216.66.86.114 local $my_ip ttl 255
# watch the MTU!
ip link set dev he-ipv6 mtu 1280
ip link set he-ipv6 up
ip addr add <prefix>::2/64 dev he-ipv6
ip route add ::/0 dev he-ipv6 mtu 1280
# fix up the routes
ip route del <prefix>::/64 dev he-ipv6
ip route add <prefix>::/64 dev br0 2>/dev/null
Side note: Don't think that scripts under /etc/ppp/ip-up.d would get
executed automaically when the interface comes up. Use something like
this instead:
root@ndogo:~# cat /etc/hotplug.d/iface/20-ipv6
#!/bin/sh
[ "${ACTION:-ifup}" = "ifup" ] && /etc/ppp/ip-up.d/he-tunnel
The connection seemed to work nicely at first. At least, all Google
searches were using IPv6 and were fast at that. However, oftentimes (in
about 80% of cases) establishing a connection via IPv6 was not
working. Pings (and thus traceroutes) showed no network outage or
other delays along the way. However, tcpdump showed wrong checksums
for a lot of TCP packets.
Only today I got an idea why this might be: wrong MTU. So I set the
MTU to 1280 in the HE web interface and on the router, too: ip link
set dev he-ipv6 mtu 1280. Suddenly, all connections work perfectly.
I've been toying around with the privacy extensions, too, but I don't know how to enable the mode "one IP per new service provider". There's some information about the PEs here but for now I have disabled them.
My flatmate's Windows computer and iPhone picked up IPv6 without further configuration.
I'm actually astonished how many web sites are IPv6 ready. So far I like what I'm seeing.
Update: While setting up an AAAA record for the blog, I forgot it had been a wildcard CNAME previously. The blog was not reachable via IPv4 for a day – that was not intended! ;-)
Find the Spammer
A week ago our server was listed as sending out spam by the CBL, which is part of the XBL which in turn is part of the widely-used Spamhaus ZEN block list. As a practical result, we couldn't send out mail to GMX or Hotmail any more:
<someone@gmx.de>: host mx0.gmx.net[213.165.64.100] said:
550-5.7.1 {mx048} The IP address of the server you are using to connect to GMX is listed in
550-5.7.1 the XBL Blocking List (CBL + NJABL). 550-5.7.1 For additional information, please visit
550-5.7.1 http://www.spamhaus.org/query/bl?ip=176.9.34.52 and
550 5.7.1 ( http://portal.gmx.net/serverrules ) (in reply to RCPT TO command)
The first source we identified was a postfix alias forwarding to a virtual alias domain; however, I had deleted the user in the latter table, such that postfix would return a "user unknown in virtual alias table" error to the sender. But because the sender was localhost, postfix would create a bounce mail. (This is known as Backscatter.)
But one day later, our IP was listed in CBL again. So I started digging deeper. How do you identify who is sending out spam? There are some obvious points to start:
- Old WordPress installations an the like that got owned
- Open Relay (mis-configured postfix)
- Spam-sending trojan (local process running)
To get a clearer image of what was really happening, I did two things. First, I implemented a very simple "who is doing SMTP" log mechanism using iptables. It went like this:
$ cut -d: -f1 /etc/passwd | while read user; do
echo iptables -A POSTROUTING -p tcp --dport 25 -m owner --uid-owner $user -j LOG --log-prefix \"$user tried SMTP: \" --log-level 6;
done
iptables -A POSTROUTING -p tcp --dport 25 -m owner --uid-owner root -j LOG --log-prefix "root tried SMTP: " --log-level 6
iptables -A POSTROUTING -p tcp --dport 25 -m owner --uid-owner feh -j LOG --log-prefix "feh tried SMTP: " --log-level 6
...
(To be honest I used a Vim macro to make the list of rules, but that's hard to write down in a blog post.)
Second, I NAT'ed all users except for postfix to a different IP address:
$ iptables -A POSTROUTING -p tcp --dport 25 -m owner ! --uid-owner
postfix -j SNAT --to-source 176.9.247.94
Then, I dumped the SMTP-related TCP flows for that IP address:
$ tcpflow -c 'host 176.9.247.94 and (dst port 25 or src port 25)'
I waited for a short time, and soon another wave of spam was sent out. Now I could clearly identify the user:
Jul 19 16:48:35 noam kernel: [5590933.619960] pete tried SMTP: IN= OUT=eth0 SRC=176.9.34.52 DST=65.55.92.184 ...
Jul 19 16:48:38 noam kernel: [5590936.616860] pete tried SMTP: IN= OUT=eth0 SRC=176.9.34.52 DST=65.55.92.184 ...
Jul 19 16:48:44 noam kernel: [5590942.615608] pete tried SMTP: IN= OUT=eth0 SRC=176.9.34.52 DST=65.55.92.184 ...
But instead of finding an infected web app, I found that the user was
logged in via SSH and was executing sleep 3600 commands. When I
killed the SSH session, the spamming stopped immediately.
Since this was not a user I know personally, I don't know what happened. My best guess is an infected Windows computer and an SSH SOCKS forwarding setup that allowed the (romanian) spammer to tunnel its connections.
One question remains: Are modern spam-drones able to steal WinSCP/PuTTY login credentials from the Registry and use them to silently set up SSH tunnels? Or was this just a case of bad luck?
mail server switchover
Today I migrated the last big part of my old server: the mail system. Since I and other people depend on this server for their day-to-day mailing, I had to switch over without losing a single e-mail. This is how I did it:
Step one: Port the configuration, make the environment run on the new server. Copy also user metadata like passwords and make sure the overall structure is working (incoming SMTP works, POP3 access, etc.)
Step two: Copy over all mails from the old server. The mails will be synced later on again, so this can happen some minutes in advance. (I actually lost a few days doing this, because I discovered unused mailboxes with 995,000 mails, >99% of them being spam. I had to ask the owner first, though, whether I could delete them.)
Now comes the time-critical path. It took me an overall 70 seconds to do steps three to five.
Step three: Stop the daemons that receive mail or give the user
access to it. For example: for s in postfix courier*; do
/etc/init.d/$s stop; done – connecting to the host will now
give a "connection refused" error message. MTAs trying to deliver mail
will usually try again ten minutes later. (So no mail gets lost.)
Step four: Sync the emails again. There might have arrived new
messages, or users have deleted some of their inbox. I used this
command: rsync -avhP --delete vmail@eris.feh.name: .
Step five: Apply iptables rules to forward connections to the new
server. This is due to the fact that DNS information is slow to
spread. For a few days I don't care whether mail.feh.name resolves
to 88.198.158.101 or to 176.9.247.89. Both will effectively talk to
the new server.
iptables -t nat -A PREROUTING -p tcp -s ! 176.9.34.52 --dport 25 \
-j DNAT --to-destination 176.9.34.52:25
iptables -t nat -A PREROUTING -p tcp -s ! 176.9.34.52 --dport 110 \
-j DNAT --to-destination 176.9.34.52:110
iptables -t nat -A POSTROUTING -d 176.9.34.52 -j MASQUERADE
iptables -A FORWARD -p tcp -d 176.9.34.52 -j ACCEPT
iptables -A FORWARD -p tcp -s 176.9.34.52 -j ACCEPT
So this establishes forwarding for SMTP and POP3. The old server will simply act as a NATing gateway to the new server.
Step six: Adjust the DNS. As said above, you can take your time for
this; but the information will eventually spread. To have an indicator of
how many connections still arrive at the old host, try iptables -t
nat -L -vn, it'll print packet and byte counts for each rule in the
NAT table.
Done! And just one minute of outage. *like*